Introduction
This article describes an optimization made into Erigon 3.1 which significantly reduced the size of internal indexes. But before diving into our recent findings, let’s first contextualize the reader into how indexing in Erigon evolved over time.
From block to transaction granularity
In Erigon 2 the indexes had block granularity. That means that if you are going to index, for example, the occurrence of a log topic, it is storing the block number where the event happened.
In that case, if the user asks the node for occurrences for that particular log topic, the database is going to answer a list of block numbers, then the code needs to traverse all the individual transactions inside that block in order to finally find the matches.
The indexes are stored in a data structure called roaring bitmap, which offers a very compact way to store continuous numbers. Having block granularity indexes benefit directly from that property as popular contracts have some appearance in every block.
However block granularity doesn’t scale well, as block size varies among chains. Chains with short intervals between blocks have smaller blocks, while chains like Ethereum mainnet which have a 12 seconds block time have more transactions.
Enter Erigon 3, where all indexes have transaction granularity. That means every index pinpoint exactly the transaction where the event occurred.
In Erigon 3 the roaring bitmaps were replaced by Elias-Fano, which is another encoding format for number sequences. It performed so well that even with a smaller index granularity (hence more data being indexed), Erigon 3 total disk size is smaller than Erigon 2.
That was the result of +3 years of research done by the Erigon team.
💡 Note: there are other changes made in Erigon 3 that have also contributed to the smaller disk size.
In order to establish a baseline, here are the disk space requirements of Erigon 3 up to chain tip (Sep/2025):
Can we do even better?
I started studying the new index format of Erigon 3 and while looking at production data I realized there were improvements that could be done in order to make the index size even smaller.
This article won’t describe how Elias-Fano encoding works, there are plenty of articles out there, but suffice to say that it incurs some overhead per key in order to store the support data structures that allow fast get/search operations inside the index.
That means that for very short sequences it would take less disk space if you DO NOT use Elias-Fano, but simply store the raw numbers instead. Now, how much data does these short sequences occur in real blockchain data? Let’s take a look at Ethereum mainnet data (as of Sep/25).
First, the number of index keys grouped by how many transaction matches it has (entries with >16 matches are grouped):
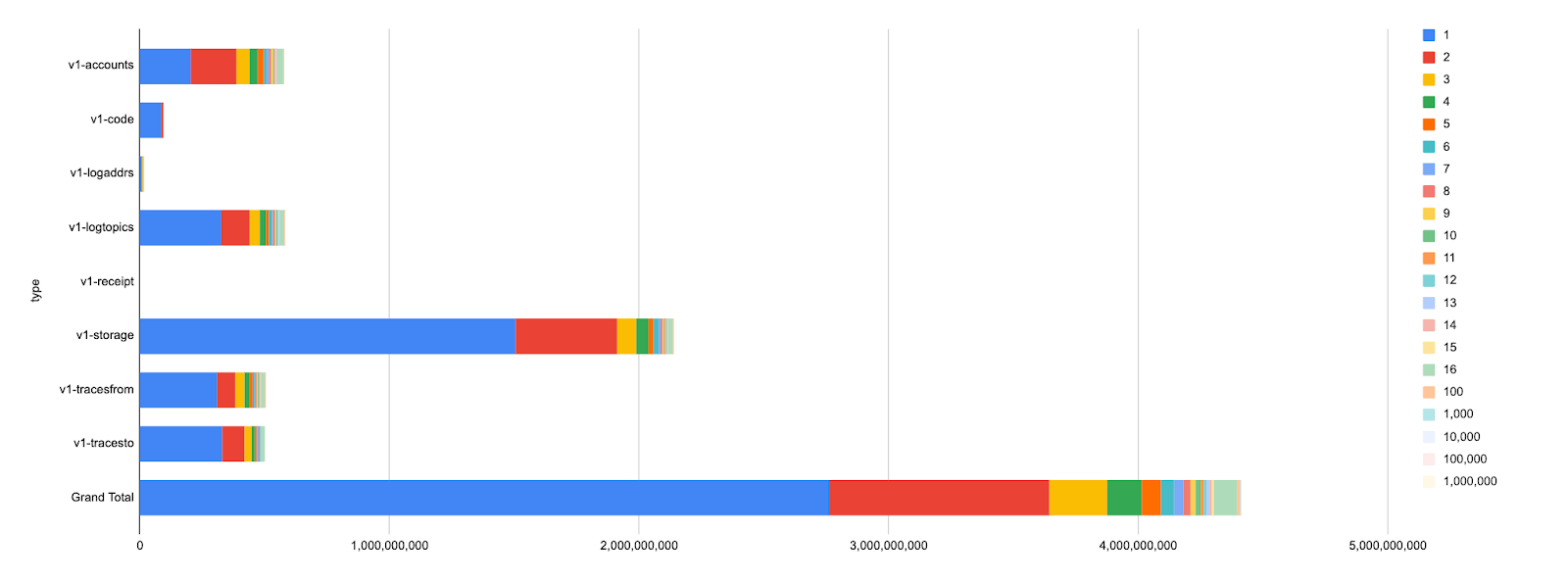
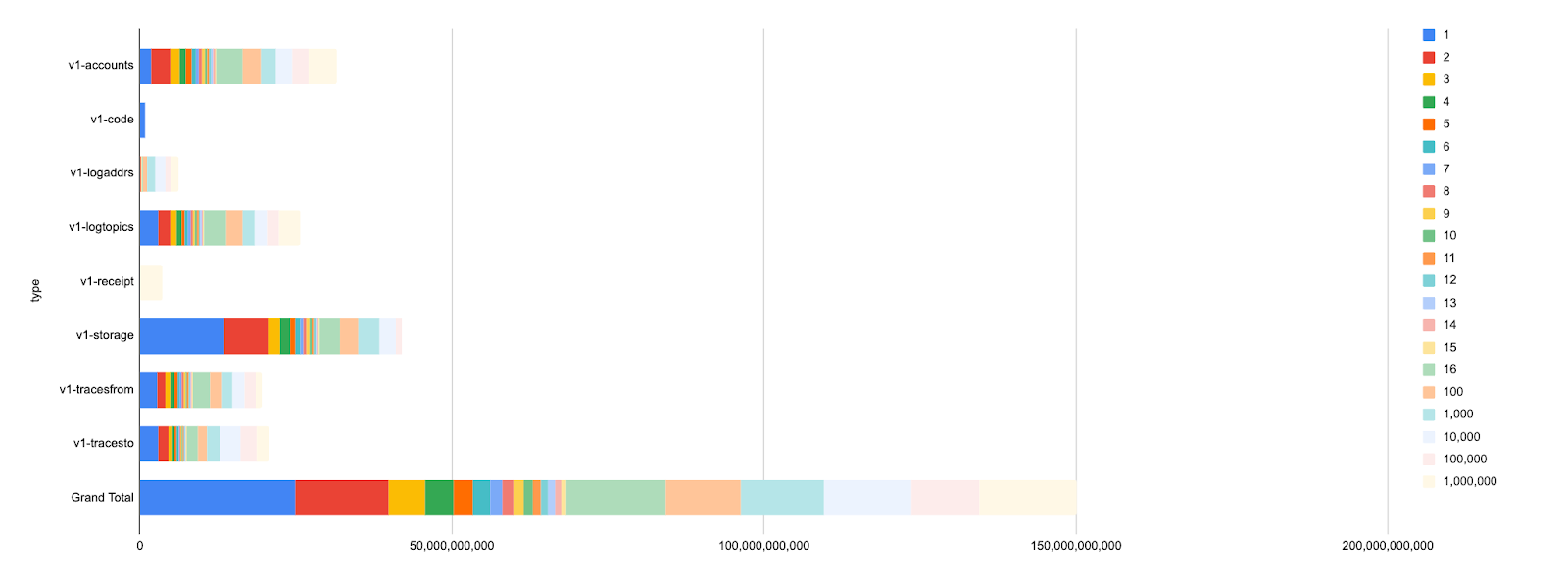
Second, the disk usage of each key index, grouped by the number of transaction matches:
![]()
The reader shouldn’t bother trying to understand the details because they are related to Erigon internal data structures. For the same reason they don’t necessarily map 1:1 to other client implementations.
The important data point here is: most of the keys in production data index only 1 or 2 transactions and they correspond to the majority of disk usage (~360GB of index values).
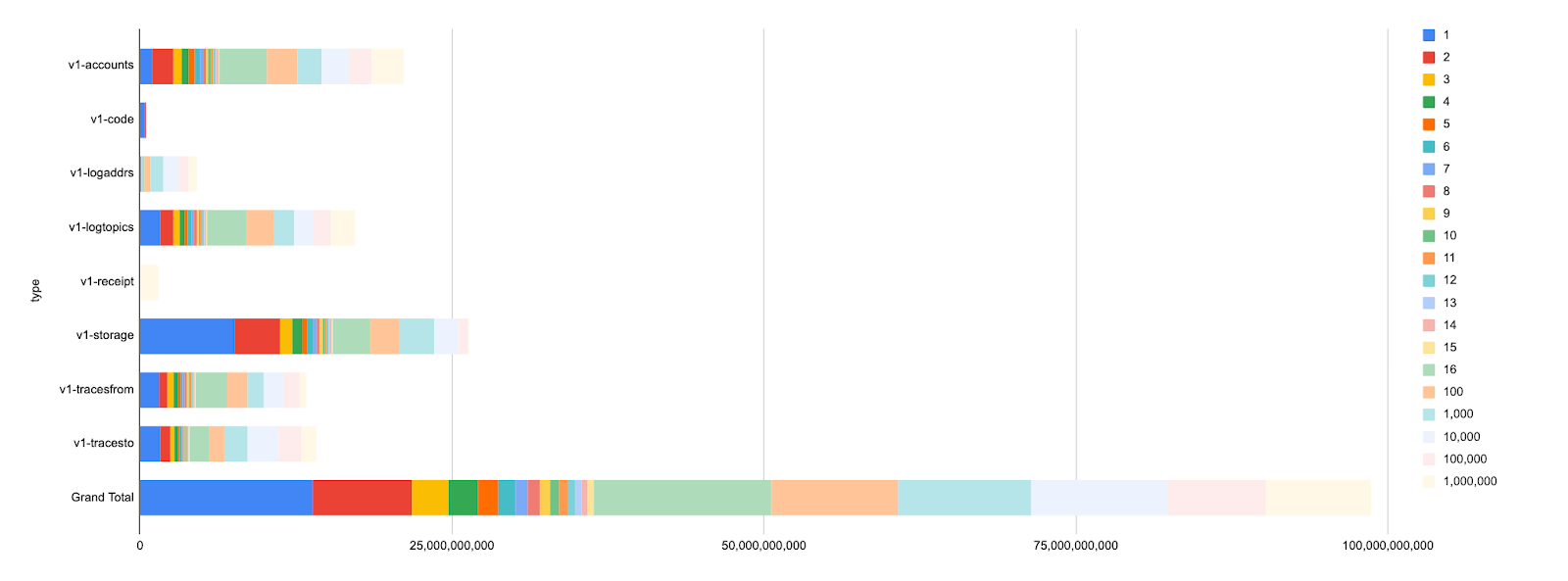
It means that by NOT using Elias-Fano for such cases would result in large disk space savings. In fact, the next chart shows a simulation where indexes with < 16 transaction matches would be naively encoded just as a concatenation of their raw values (uint64):
The naive solution would reduce the disk usage from +360GB to 150GB, almost 60% reduction. In the end I implemented an even more optimized encoding by taking advantage of the file format Erigon 3 is using and the final index size is ~98GB.
On Polygon (bor-mainnet) the disk savings were even bigger, over 900GB, resulting in the entire archive node going from 5.8TB to 4.9TB. For the record, here are the index values histogram of bor-mainnet on Erigon 3.0 (~1.3TB):
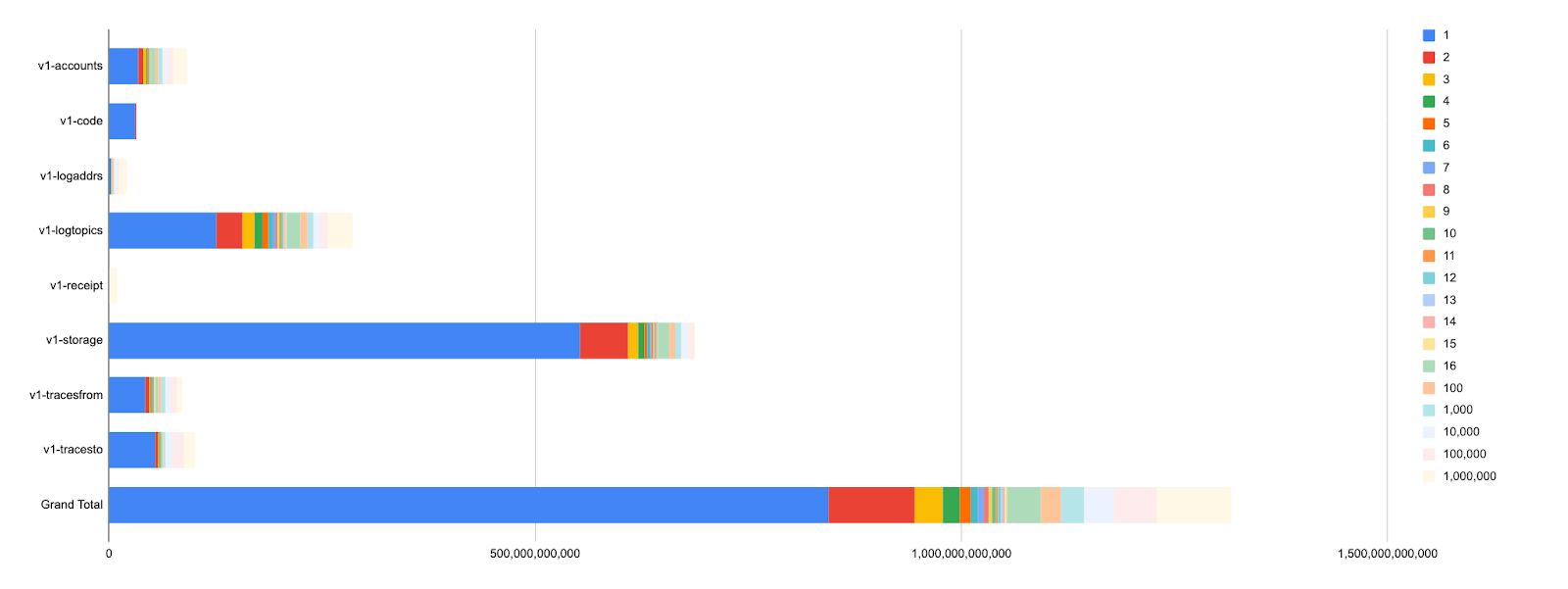 And here is the optimized simulation of it (~290GB):
And here is the optimized simulation of it (~290GB):
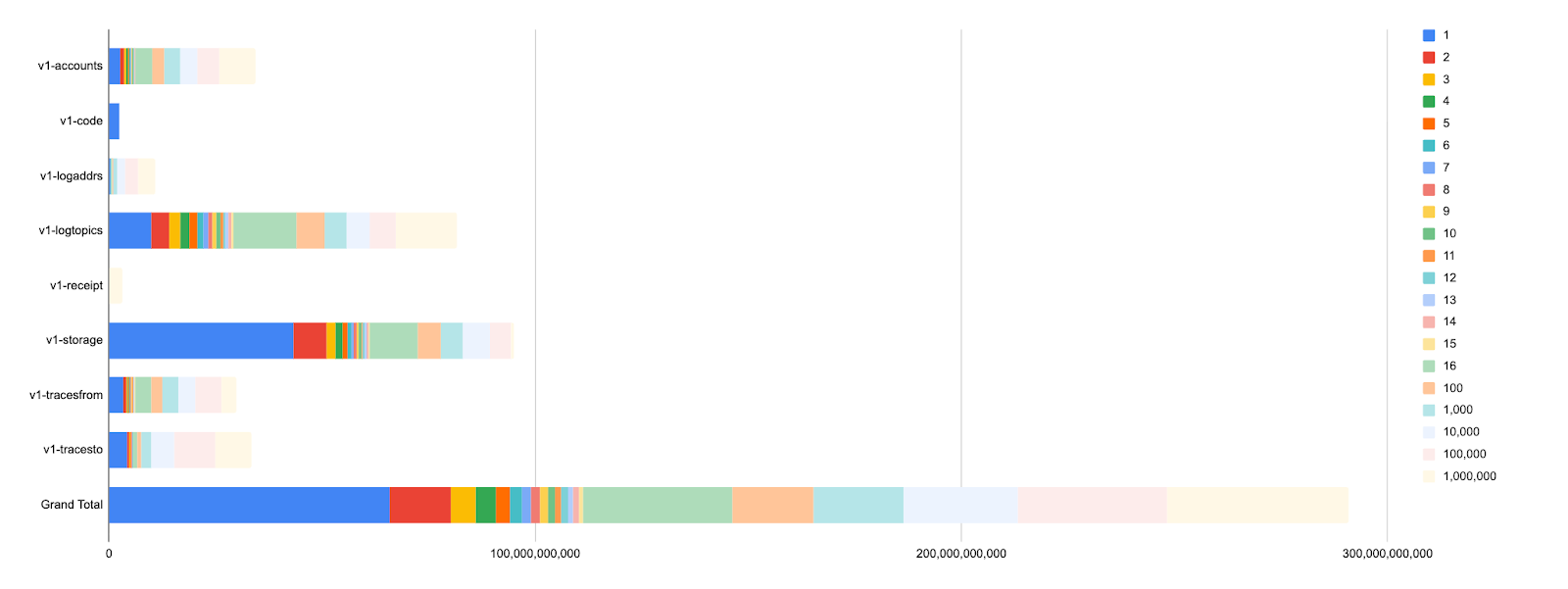
Result: much smaller archives in Erigon 3.1
All indexes were regenerated on Erigon 3.1 and the table below shows the gains per supported chain (only index files):
| Chain | Erigon 3 | Erigon 3.1 | Savings |
|---|---|---|---|
| Ethereum Mainnet | 504GB | 252GB | -252GB (-50%) |
| Gnosis | 179GB | 102GB | -77GB (-43%) |
| Polygon | 1,900GB | 970GB | -930GB (-49%) |
| Sepolia Testnet | 142GB | 72GB | -70GB (-49%) |
| Holesky Testnet | 101GB | 45GB | -56GB (-56%) |
| Hoodi Testnet | 12GB | 6GB | -6GB (-50%) |
And here are the differences considering the entire node size (note: the savings column doesn’t match exactly the previous table because there are other small differences other than indexes between the compared nodes):
| Chain | Erigon 3 | Erigon 3.1 | Savings |
|---|---|---|---|
| Ethereum Mainnet | 2,050GB | 1,770GB | -280GB (-14%) |
| Gnosis | 600GB | 539GB | -61GB (-10%) |
| Polygon | 5,780GB | 4,850GB | -930GB (-16%) |
| Sepolia Testnet | 863GB | 780GB | -83GB (-10%) |
| Holesky Testnet | 342GB | 277GB | -65GB (-19%) |
| Hoodi Testnet | 58GB | 53GB | -5GB (-9%) |
Comparison of Erigon 3.1 (Ethereum mainnet) vs other clients* **:
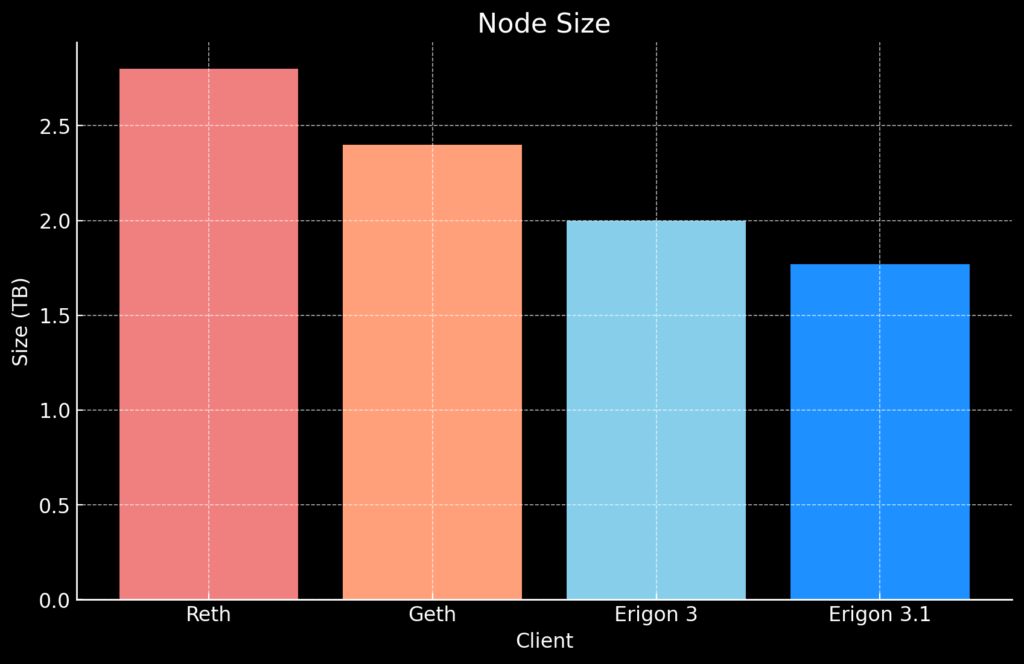 * Reth snapshot from Merkle, image from 2025-09-01. Geth using the path-based archive mode. Erigon 3/3.1 synced up to mid-09/2025.
* Reth snapshot from Merkle, image from 2025-09-01. Geth using the path-based archive mode. Erigon 3/3.1 synced up to mid-09/2025.
** Special thanks to Chase Wright who provided data on Reth/Geth from his nodes.
Final thoughts
Erigon 3.1 reaffirms its position as the most space efficient archive node implementation. The state snapshots introduced in Erigon 3.0 established a new foundation enabling a whole new set of possible optimizations.
I’m confident there are many more optimizations waiting to be uncovered as we continue to study production data patterns more closely. Looking forward to bringing more disk space savings in the future!
